How good a detective is an AI?
A Sherlock Holmes board game as an LLM-agent eval
It started at a dinner. A few friends and I sat down to play Sherlock Holmes Consulting Detective — an open-ended deduction game where you’re handed a Victorian London case, you pick which people and places to go investigate, and each lead hands you a passage of text to read. Most of the game is reading, cross-referencing, and arguing at the table. At the end you answer the case’s questions and score yourself against Holmes himself — including how few leads you needed. The answers sit in the back of the booklet, printed upside-down, daring you not to peek.
We walked straight into the trap the case is built around. There’s an obvious victim — a man every detail points to as the target — and we hung our whole theory on him. But one clue wouldn’t sit still. The morning after the murder, the killer goes back to a shipping office and scans the passenger list again. We re-read the passage three times. Why would he do that? If he’d already killed the person he was after, what was he still looking for? Something didn’t close, and none of us could say what.
So, at 2am — out of wine and out of steam — we did the forbidden thing: we turned the booklet over. And there in the answer key, a name we’d treated as background all evening stepped forward as the real undercover agent — alive, never caught, the person the killer was still hunting. The passenger-list visit wasn’t a loose end. It was the case. We’d held the contradiction in our hands — we’d even said out loud that it was strange — and we’d read right past it.
That non-closing feeling is the thing that stuck. We weren’t short on information; we had every clue we needed. We were short one inference — the small, second-order turn from “that’s a strange thing for the killer to do” to “then the whole story we’ve built is wrong.” So I started to wonder: how good a detective is an AI, really? Handed the same leads, would an LLM agent read that behavior as a behavior, notice it broke the obvious story, and follow it to the live agent we’d missed?
To find out, I turned the game into an eval for LLM agents. The agent plays the Irregulars — the Baker Street street kids Holmes sends out to do his legwork.
On its first run, Claude Fable 5 tied Holmes — in the hard mode, where you don’t even get to see the questions until the investigation is over.
That’s the headline. But the score isn’t the story. The interesting part is the two distinct ways these agents fail — and that the harder failure, the exact one that beat us at dinner, has a clean fix that turned out to be less about model size than I expected.
Why a board game is a surprisingly honest agent eval
What I didn’t see at the table that night is that we’d just lost to an unusually clean agent benchmark. Most agent benchmarks have a problem: the answer is somewhere in the context, or the task is gameable, or “success” is graded loosely. A printed detective game sidesteps all three by construction:
- The solution is physically hidden. Those upside-down answers never enter the agent’s allowed workspace; reading them would be a detectable protocol violation, and I audit for it.
- Information has a price. Thinking, re-reading, and cross-referencing are free and unlimited. But acting — visiting a location to pull a new clue — is the only way to get new information, and every new clue beyond what Holmes used costs points. That’s a miniature of real agent economics: every tool call costs something.
- It rewards comprehension, not retrieval. Clues are behaviors and details you have to assemble into one coherent story; none of them hands you the answer.
The mechanics that make this auditable, in one breath: the agent works in a sandbox containing only what it’s allowed to see; a deterministic Game Master (plain Python, not an LLM) serves clues verbatim and logs everything; visits cost points and the solution lives outside the agent’s reach; and a separate validator — the only component that reads the solution — cross-checks the log against the answers afterward. (More on the isolation in How it’s built below; full mechanics in the repo.)
A note on words: I’ll call it cheat-resistant, not cheat-proof. It’s a commercial game, so I can’t rule out that some of the case leaked into pretraining, or that an agent could steer its exploration with latent knowledge it never names in an answer. What I can show is that the agents’ mistakes are consistent with only the information they were served — strong evidence, not proof.
The two ways it fails
Across a ladder of models (Claude Haiku 4.5 → Claude Sonnet 4.6 → Claude Opus 4.8 → Claude Fable 5), two failure modes show up again and again. They’re worth naming because they’re not specific to board games — they’re how LLM agents fail at any multi-step retrieval-and-reasoning task.
Failure 1 — Execution: preferring what you generated to what you retrieved
The case’s undercover agent uses a cover name. Claude Fable 5 — the strongest player overall — actually found the real name in a served clue and wrote it into its own notes. Then, at answer time, it crossed it out and replaced it with a cleverer name it had constructed itself: an anagram of a passenger-list name that looked like it “decoded” into something elegant.
It had the right answer, retrieved, on the page in front of it. It overrode it with a guess it generated, because the guess felt more clever. This happened in both of Claude Fable 5’s clean single-pass runs. The checkpointed run is revealing: a third Claude Fable 5 run had to be restarted mid-game (rate-limiting), so it resumed as a fresh agent reading only its externalized notes — and, taking that retrieved fact at face value instead of re-deriving it, it kept the correct name. It was the only Claude Fable 5 run to both escape the decoy trap and name the agent correctly — and it got there precisely by trusting a fact in its notes over a freshly-generated guess.
If you build RAG or research agents, you know this bug — the one where the model confidently hallucinates over a document it just retrieved. Here it is, isolated and measurable: recency plus a bias toward self-generated content beats recalled fact. The freshly-generated inference (recent, mine) wins over the served fact (old, someone else’s) buried in a long append-only history.
Failure 2 — Comprehension: the obvious suspect is a decoy
This is the trap from the dinner, named precisely. The murdered man is, on the surface, the obvious “agent” — a former detective, an American just arrived in London. Every detail invites you to conclude he’s the target. He isn’t: the real undercover agent is the living woman the killer is still hunting, and the tell is the behavior we couldn’t explain at the table — you don’t hunt a corpse.
Call this the decoy trap: the obvious suspect is a stand-in, and the real answer is the one you have to infer is still out there. Escaping it — reading a clue as a behavior, noticing it contradicts the obvious story, concluding the obvious story is wrong — is the second-order turn we failed to make. And it’s where almost every configuration falls down: a single-agent “methodical detective” prompt, run across nine playthroughs of this one case, fell for the decoy trap 9 times out of 9.
These two failures organize everything else: execution errors (you understood it and fumbled it) versus comprehension errors (you never understood it).
What actually fixes each failure (the evidence)
I tried a ladder of interventions, each isolating one lever. The honest summary: most things help the easy failure (execution) and the process; the hard one (comprehension) was stubborn until I changed the agent topology.
- A generic “good investigator” prompt (exhaust the free material first, cite your sources, build one model of the world, distrust the obvious). This cleaned up the process beautifully — exploration got disciplined, fabrication (the anagram) disappeared. But comprehension didn’t move: the decoy trap held 9/9. You can teach an agent to behave like a good investigator without teaching it to understand the case.
- Letting it know the questions up front (instead of the hard mode). This can touch comprehension — but it’s model-dependent. Claude Sonnet 4.6 jumped and cracked the trap; Claude Opus 4.8 didn’t benefit; Claude Haiku 4.5 couldn’t use it. The lesson: the trap is built during the investigation, so a hint during the investigation helps; cleaning up only at answer time is too late.
Neither reliably broke the comprehension trap. The thing that did was splitting the agent in two.
Split comprehension from exploration
The move: instead of one agent that both explores and reasons, use two agents that cooperate:
- A Theorist — the comprehension engine. It has no access to the world: it can’t
grep, can’t visit anything, never sees the directory or the GM’s raw output. Its only job is to maintain a single model of the world, label every fact with its source, hunt loose ends, try to falsify its own leading hypothesis, and decide what to investigate next. It’s re-spawned fresh every turn from an externalized ledger, so it never accumulates a contaminated transcript of dead-ends — which means the model of the world it “maintains” doesn’t really live in the agent at all: it lives in the ledger text and is rebuilt, in-context, every turn. The case-model is a document the Theorist rewrites, not a state it holds. (That’s the same property that helped the checkpointed Fable run keep the right name: when your world-model is a file, it’s easier to trust the written fact over a fresh guess.) It doesn’t see the questions until it decides to close. - An Explorer — the perception/action engine. It has the workspace and the Game Master. It takes a loose-end from the Theorist, resolves the name→address, visits, and relays the clue back verbatim. It’s explicitly forbidden from concluding anything about the case.
- A conductor between them is a pure verbatim pipe.
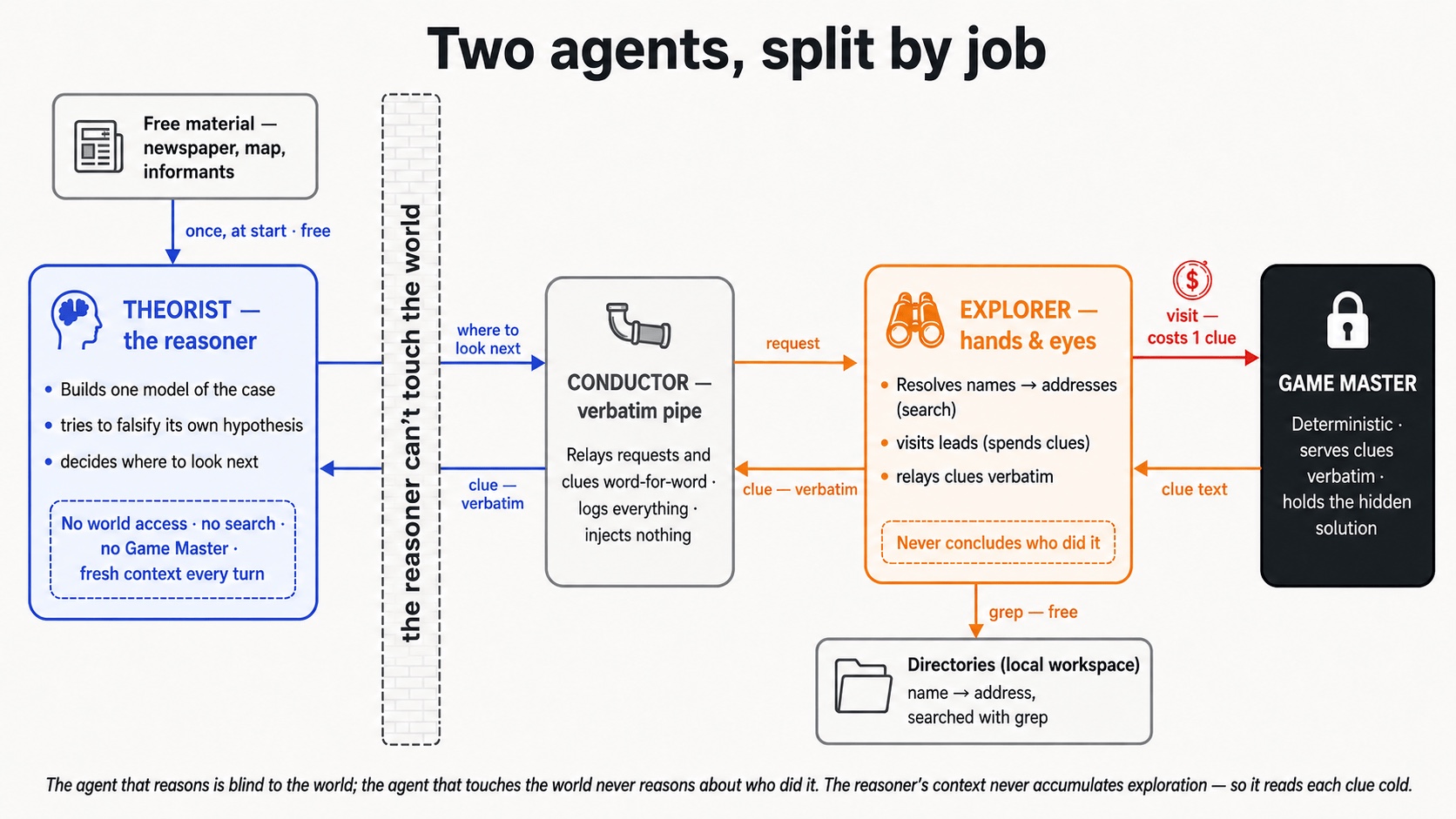
Why would this help? Not because the context is cleaner — the clean-monolith control below keeps it clean and still falls. My read is that the Theorist never does the exploration: it never builds the obvious-reading-first frame that hunting for clues instills, and it isn’t committed to a story its own legwork kept reinforcing. Blinded from the mechanics of exploring, it reads each clue cold. And here’s the part worth being precise about: this isn’t the Theorist connecting facts the monolith couldn’t. The monolith had the same served clues, the same model, and the same fresh-memory setup — stitching scattered facts into a relation is something both can do. What differs is the prior that stitching runs under, plus the standing order that shapes it: the Theorist’s one job is to falsify its leading hypothesis, not defend it. The second-order move isn’t “connect A and B” — it’s “use B to kill the hypothesis that A made tempting.” Given the same still-hunting clue, the monoliths that reached it still misread it — but the Theorist made the call out loud.
By then a few facts about the case had surfaced — the murdered man and the hunted woman were siblings, and the people behind the murders had tortured her for hours trying to get a name — and the Theorist put them together:
“They tortured the sister for hours to extract an identity. If the dead brother were the infiltrated agent, they’d already have him — they wouldn’t need to drag a name out of her. The killer is still acting on an open order. Therefore the agent is alive, and it isn’t the dead man.”
That’s the second-order inference, made in plain text, by an agent that never touched a directory.
“But is it really the architecture?” — interrogating my own conclusion
This is where the article has to practice what it preaches. “Comprehension is a topology problem” is a big claim, and good detective work — the entire subject of this article — means distrusting your obvious conclusion until you’ve ruled out the alternatives. There were two.
Alternative 1: maybe it’s just the clean context. The Theorist gets a fresh context each turn; the failing monolith doesn’t. So I built a clean monolith: a single agent — still Claude Opus 4.8 — that explores and reasons itself, but is re-spawned fresh each turn with the same externalized memory the Theorist gets. Same cleanliness, no role-split. Across 3 runs it fell for the trap 3/3. One run even visited the shipping office, saw the killer still hunting, and still concluded the dead man was the agent. Clean context didn’t reproduce the effect.
Alternative 2: maybe it’s just that Claude Opus 4.8 is the smart one. So I ran the duo with Claude Sonnet 4.6 in both roles — a weaker model in the reasoning seat. It broke the trap, with the same second-order inference, and held it when a later clue re-baited it (revealing the dead man’s old detective past — the exact detail that re-snared all three Claude Opus 4.8 monoliths).
Here’s the whole evidence matrix, which is the part of this article I’d most want a skeptic to audit:
| Configuration | What it is | Escaped the decoy trap? |
|---|---|---|
| Baseline | one agent per model, no scaffolding (the model ladder) | mixed: Claude Fable 5 escaped; Claude Haiku 4.5 / Claude Sonnet 4.6 / Claude Opus 4.8 fell |
| Methodical-prompt monolith | one agent with generic “good investigator” instructions | fell 9/9 (Claude Opus 4.8 among them) |
| Clean-context monolith | one agent (Claude Opus 4.8) that explores and reasons, re-spawned fresh each turn | fell 3/3 |
| Reasoner + explorer duo | Claude Opus 4.8 reasons, Claude Sonnet 4.6 explores | broke 2/2 |
| Same duo, weaker reasoner | Claude Sonnet 4.6 in both roles | broke 1/1 |
Where it applies, each of these is N=3 per model, run independently — I’m reporting the binary trap outcome, not a hand-picked best run. (The baseline ladder and the methodical prompt are 3 runs per model; the controls and the duos are the run counts shown.)
Read across it and the careful claim falls out:
Model capability alone was neither necessary nor sufficient. Not sufficient: a strong model (Claude Opus 4.8) falls for the trap as a monolith, even with clean context. Not necessary: a weaker model (Claude Sonnet 4.6) breaks it in the right role-split. The lever that moved the comprehension failure wasn’t the model and wasn’t the clean context — it was separating the agent that reasons from the agent that explores. (One model, Claude Fable 5, escaped solo — so capability can get there. It’s just not the lever that generalized.)
How it’s built (and why you can trust it)
The harness itself — the deterministic Game Master, the command surface, the scoring, the directories, and the duo’s wiring — is documented in the repo. The one piece worth restating here, because every result in this article rests on it, is the isolation.
Isolation is convention + audit, not a hard sandbox: the agent’s directory holds only permitted material; the GM’s internals and the solution live outside it; the prompt forbids leaving. The Game Master is plain Python, not an LLM — it serves clues verbatim, logs every event, and never holds the solution in memory, so it can’t leak it even by accident. A separate validator — the only component that reads the solution — cross-checks the served log against the answers, and knowledge with no served origin gets the run discarded. In practice the errors are the support: agents’ correct case-specific facts traced back to served clues, and even their wrong answers were explainable as transformations of served text (Claude Fable 5’s anagram was built from a name on a served passenger list, not conjured from outside). The tell of leakage would be the opposite — an agent naming the actual hidden solution it was never given — and that never appeared.
The honest part (what I ruled out, and what I couldn’t)
Two alternatives these controls ruled out as sole explanations in this setup: clean context alone didn’t reproduce the effect, and the big model wasn’t required. What honestly survives:
- It’s one case. The decoy trap is a single instance of second-order reasoning in a single case. Two duos breaking it three times total is a strong signal, not a law. Replicating on a second case (with its own trap) is the obvious next step — and the one thing I can’t yet claim.
- The bottleneck moves. Solving comprehension just reveals the next wall: actually reaching the leaf-clues that supply proper names. The duo understood the whole plot and still missed the agent’s literal name — it lived behind a thread it never pulled.
- Mundane things matter as much as the clever ones. In one duo run, the biggest single jump in score came not from the architecture but from the Explorer searching the directory with the right accent — an earlier run had missed an entire storyline because its
grepwas accent-sensitive and silently returned nothing. A Unicode-normalization bug cost more points than the scaffolding earned. Robust, boring search is underrated. - The score is noisy; the binary result isn’t. Using an LLM as the grader introduces real variance (±25 points on the same answers, Claude Fable 5 vs Claude Opus 4.8). Treat every number here as color. The claim I stand behind is binary and grader-independent: did it fall for the decoy trap, or not.
Lessons for people building agents
- Retrieved beats generated — but your agent doesn’t believe that. The deepest failure here is an agent overriding a fact it had retrieved with a guess it generated. If your RAG/research agent ever “improves” on a document it just pulled, this is that bug, isolated.
- For comprehension, topology is a lever orthogonal to model size. The same model that falls for the decoy trap stops falling for it when you give a dedicated agent one job — falsify hypotheses — and keep the exploration mechanics out of its context. A bigger model can also get there (Claude Fable 5 did) — but the role-split fixed models that fail solo, and did it with a weaker model in the reasoning seat. That’s the planner/executor pattern, with a sharp, measurable reason it works here: doing the investigation instills a pull toward the obvious reading; an agent that only reasons — and never investigates — doesn’t pick it up. (And it isn’t merely a clean-context trick: a single agent with clean context that still explores falls anyway.)
- Bottlenecks are layered. Fixing comprehension surfaced an exploration-coverage problem you couldn’t see before. Expect to find the next wall behind the one you just removed.
- Watch your judge, and your
grep. The flashy failure modes are real, but a noisy LLM grader and an accent-sensitive search quietly moved more points than anything else. Rigor is the product.
What’s next
- Replicate the comprehension result on a different case (kill the single-case caveat).
- A “naming-completeness” pass so the duo stops leaving named-but-unidentified actors on the table.
- Longer-horizon cases, a red-team of the isolation, and non-Anthropic models in the same harness.
The setup is a board game. The findings aren’t about board games — they’re about the two ways agents fail at thinking, and the surprising news that the harder one might be something you can wire around. None of us made that turn at dinner. What still surprises me is that the agent that finally did wasn’t the smartest one at the table — it was the one I’d walled off from the hunt entirely, and left with nothing to do but think.
A note on models: I used Anthropic’s models throughout — as examples, and for practicality, because they gave me a clean capability ladder to vary, topped by Claude Fable 5 (the strongest player here). Anthropic temporarily disabled Claude Fable 5 on June 12; I’d gotten only three runs with it by then, which is why every Claude Fable 5 result here rests on at most three playthroughs. The findings are about agent topology, not any one vendor or model; the same harness would run others.
A note on the game: the case comes from Sherlock Holmes Consulting Detective: Baker Street Irregulars, published by Space Cowboys. It’s a commercial product, so I paraphrase its case material rather than reproduce it, and quote only the agents’ own reasoning. The publisher’s cover art appears only as this page’s link-preview image — shown for identification and commentary, © Space Cowboys, and not covered by this site’s CC BY license.